

Update: Video Introduttivo al corso qui
La crescente sofisticatezza dei Large Language Models (LLM) ha trasformato il modo in cui le organizzazioni sviluppano applicazioni basate sull’intelligenza artificiale. Non è più sufficiente l’interazione diretta con il modello; è emersa la necessità di tecniche avanzate per garantire che l’output sia preciso, pertinente e allineato agli obiettivi aziendali o anche solamente a quelli personali. Questo corso si focalizza su due discipline fondamentali per gestire al meglio le applicazioni basate su LLM: il Prompt Engineering e il Context Engineering.
Il Prompt Engineering è definito come la scienza (o l’arte) di formulare istruzioni (o prompt) per guidare gli LLM a produrre risultati ottimali. Sebbene cruciale, il prompting rappresenta solo la prima fase di controllo. Il Context Engineering ne è l’evoluzione avanzata.
Il Context Engineering è la pratica di plasmare e controllare l’ambiente informativo completo che un sistema AI o un Agente percepisce. Questo ambiente include i prompt di sistema, la memoria della conversazione, l’accesso agli strumenti e l’insieme dei dati esterni. L’obiettivo è ottimizzare l’utilità di tutti i token inclusi nel campionamento del modello, superando i vincoli intrinseci degli LLM. Controllare e modellare ogni parte di questo contesto – dalle istruzioni iniziali alle interfacce degli strumenti – è essenziale per assicurare che l’LLM si comporti come previsto. Molti funzionamenti errati nelle architetture AI più complesse, come gli Agenti, non derivano da un modello debole, ma piuttosto da un contesto inadeguato, spesso dovuto a informazioni mancanti o mal formattate, che portano l’LLM a compiere l’azione errata.
Prompting per Chatbot Conversazionali
1.1. Modelli Conversazionali (Chat): Il Paradigma Intrinseco
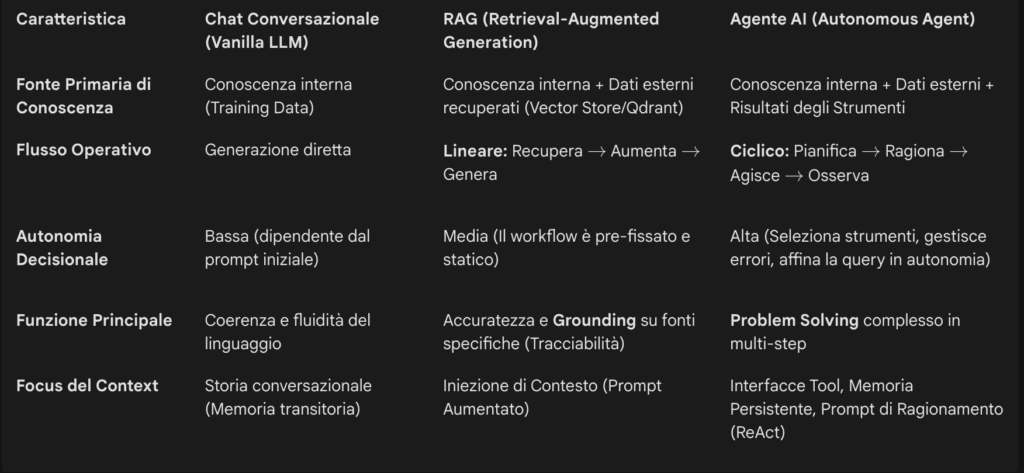
I modelli conversazionali vanilla, come ChatGPT, Claude o Gemini nella loro forma base, rappresentano l’architettura più semplice di applicazione LLM. La loro architettura si basa principalmente sulla conoscenza interna acquisita durante la fase di addestramento su corpus di dati massivi.
Architettura e Contesto Intrinseco
L’LLM riceve una richiesta e genera una risposta basandosi sulla propria comprensione linguistica e sulla distribuzione statistica dei dati di addestramento. L’unica forma di memoria a breve termine disponibile è la finestra di contesto (context window). Questa finestra include il prompt iniziale di sistema (che definisce il ruolo e le regole), e la storia della conversazione (message history). Se la conversazione supera la lunghezza massima della finestra, i messaggi più vecchi vengono troncati o compressi per fare spazio ai nuovi.
Limitazioni e Necessità di Controllo
Questa architettura presenta due limitazioni critiche. In primo luogo, i modelli soffrono del problema del knowledge cut-off : la loro conoscenza si interrompe alla data dell’ultimo aggiornamento del training set, rendendoli incapaci di rispondere a domande su eventi recenti o informazioni proprietarie. In secondo luogo, sono intrinsecamente soggetti a allucinazioni – la tendenza a generare risposte coerenti e convincenti ma fattualmente scorrette.
Un elemento fondamentale da considerare è che un LLM, essendo addestrato sull’80% del web pubblico (come il Common Crawl), tende a produrre risposte che sono, per loro natura, la media dell’informazione disponibile su Internet. Senza una guida specifica e un prompt ben definito, l’output sarà generico e privo di insight specifico per un pubblico o contesto aziendale preciso. Questo è il motivo per cui l’ingegneria del prompt è cruciale in questa fase: è l’unico vettore per infondere un’identità o una specificità che contrasti la tendenza del modello a produrre contenuti troppo “generalisti”.
1.2. Retrieval-Augmented Generation (RAG): Grounding Dinamico e Workflow Lineare
Per superare i limiti di conoscenza obsoleta e le allucinazioni tipiche dei modelli conversazionali di base, la comunità AI ha adottato la tecnica della Retrieval-Augmented Generation (RAG).
Il Flusso Statico del RAG
Il RAG connette l’LLM a fonti di dati esterne (come documenti proprietari, database o archivi in tempo reale), permettendogli di recuperare informazioni rilevanti prima di formulare una risposta. Il processo RAG tradizionale è fondamentale e segue un flusso statico e lineare:
- Retrieve (Recupero): La query dell’utente viene trasformata in un embedding (rappresentazione vettoriale). Questo vettore viene utilizzato per eseguire una ricerca di similarità su un Vector Store (ad esempio, Qdrant ), che contiene gli embedding della conoscenza esterna. Il risultato è un insieme di frammenti di documenti (chunk) rilevanti per la query.
- Augment (Aumento): I frammenti recuperati vengono aggiunti alla finestra di contesto dell’LLM, insieme al prompt originale dell’utente. Questo crea il prompt aumentato.
- Generate (Generazione): L’LLM genera la risposta finale, istruito a usare i dati aggiuntivi come unica base fattuale per l’output.
RAG come Meccanismo di Riferibilità Aziendale (Traceability)
Il RAG non è solo un miglioramento tecnico delle prestazioni; è un requisito essenziale per la fiducia e l’adozione in ambienti regolamentati. Il prompt RAG è tipicamente strutturato per istruire l’LLM a rispondere solo in base al contesto fornito. Questo vincolo sulla risposta ha un’implicazione profonda: l’output generato dall’LLM diventa tracciabile alla fonte esterna (i documenti recuperati).
Quando si usa un LLM vanilla, non c’è modo di verificare se la risposta sia vera o sia una allucinazione basata sulla memoria interna del modello. Con il RAG, l’LLM è costretto a fondare la sua risposta (grounding) sul contesto recuperato. Ciò trasforma il RAG da una semplice ottimizzazione delle prestazioni in un fondamentale meccanismo di conformità e verifica. Questo elemento di tracciabilità è cruciale per l’implementazione in scenari aziendali dove l’accuratezza e la riferibilità sono requisiti non negoziabili.
Per mantenere l’efficacia del RAG, è vitale gestire l’aggiornamento dei dati. I documenti esterni e le loro rappresentazioni embedding devono essere aggiornati in modo asincrono (spesso tramite flussi di automazione come quelli realizzabili in n8n) per prevenire l’uso di informazioni stale (obsolete).
1.3. Agenti AI: Autonomia, Ragionamento e Tool Use
L’evoluzione successiva ai sistemi RAG è rappresentata dagli Agenti AI Autonomi. Questi sistemi non si limitano a recuperare informazioni e rispondere; sono capaci di operare con un grado significativo di autonomia e di prendere decisioni dinamiche.
Il Paradigma Autonomo
Gli Agenti AI sono concettualmente paragonabili a “stagisti intelligenti” ai quali si possono delegare compiti completi. Il loro flusso operativo non è più lineare (Retrieve -> Augment -> Generate), ma ciclico e decisionale. Il processo si basa sul ciclo Pianifica -> Ragiona -> Agisce (Act).
- Pianifica (Plan): L’Agente scompone un obiettivo complesso in sotto-task gestibili.
- Ragiona (Reason): Utilizzando tecniche come il Chain-of-Thought (CoT) o ReAct, l’Agente decide quale sia il passo logico successivo e quale strumento utilizzare.
- Agisce (Act): L’Agente esegue un’azione chiamando uno Strumento (Tool) esterno (ad esempio, un’API, un motore di ricerca, un database).
A differenza del RAG tradizionale, che segue un workflow statico, l’Agente AI possiede l’elemento di autonomia e agency. L’Agente analizza continuamente il contesto e l’intento dell’utente, decidendo dinamicamente se è necessario raffinare una query, filtrare risultati irrilevanti o richiamare un altro strumento. Quando un Agente incorpora capacità di retrieval dinamico, si parla di Agentic RAG, un sistema che può decidere autonomamente come trovare l’informazione migliore e persino criticare le proprie risposte.
Context Engineering per Agenti
Negli Agenti, il Context Engineering diventa l’elemento critico di controllo. L’ingegnere deve controllare non solo il prompt di sistema, ma anche l’interfaccia degli strumenti (Tool Interfaces) e la memoria persistente.
Architetture come LangChain (utilizzate in piattaforme low-code come n8n ) astraggono il contesto in due componenti principali che lo sviluppatore può manipolare :
- Contesto Transitorio (Transient Context): Varia ad ogni invocazione del modello. Include il prompt di sistema e la cronologia immediata della chiamata.
- Contesto Persistente (Persistent Context): Strumenti disponibili e memoria a lungo termine.
Costo Operazionale vs. Adattabilità
Gli Agenti AI offrono una maggiore flessibilità e capacità di multi-step reasoning per task complessi rispetto ai sistemi RAG statici. Tuttavia, questa autonomia introduce un trade-off critico: il costo.
Il ciclo decisionale Plan/Reason/Act richiede chiamate multiple all’LLM. Ad esempio, una richiesta complessa può innescare una chiamata per la pianificazione, una per la formulazione della query allo strumento, una per l’esecuzione del tool, e infine, una per la sintesi del risultato. Questo aumento del numero di invocazioni dell’LLM (e l’uso di tecniche di ragionamento più complesse come Chain-of-Thought) aumenta significativamente i costi operazionali rispetto a un RAG tradizionale, che esegue tipicamente una singola chiamata LLM per ogni query. Le organizzazioni devono bilanciare l’investimento iniziale e i costi operativi più elevati degli Agenti dinamici con i benefici in termini di adattabilità e risoluzione di problemi complessi ed evolutivi.
1.4. Tecniche di Prompting Fondamentali (Base per Chat)
Il Prompt Engineering stabilisce le basi per tutte e tre le architetture, fornendo le istruzioni essenziali per guidare l’LLM. Sebbene esistano tecniche avanzate specifiche per RAG e Agenti, alcune metodologie sono fondamentali per qualsiasi interazione.
Zero-Shot, Few-Shot e Chain-of-Thought
Queste tecniche definiscono la quantità di contesto istruttivo fornito per completare un compito:
- Zero-Shot Prompting: Implica fornire al modello una istruzione o una domanda diretta senza fornire esempi di input-output. È la tecnica più semplice, spesso sufficiente per compiti di base come il riassunto o la traduzione.
- Few-Shot Prompting: Richiede la fornitura di alcuni esempi (tipicamente da tre a cinque) di coppie input-output che illustrano il formato, lo stile o la logica di risoluzione desiderata per un compito specifico. Questo è efficace per compiti in cui il formato di output è fondamentale.
- Chain-of-Thought (CoT) Prompting: Questa è una tecnica che migliora le capacità di ragionamento dell’LLM. Consiste nell’istruire il modello a “pensare passo dopo passo” (“Let’s think step by step”) prima di fornire la risposta finale. Esistono due varianti :
- Zero-Shot CoT: Si aggiunge semplicemente la frase di istruzione al prompt, senza esempi.
- Few-Shot CoT: Si forniscono esempi completi di ragionamento risolto, inclusi i passaggi intermedi.
CoT è un concetto precursore delle logiche agentiche più complesse come ReAct. Costringendo l’LLM a esternalizzare la sua logica decisionale, il modello stabilizza il processo di risoluzione e aumenta la precisione.
Prompting con Persona e Istruzioni Sistemiche
Per contrastare la tendenza degli LLM a produrre informazioni medie e generiche , è prassi utilizzare prompt che definiscano esplicitamente un ruolo (persona) o un insieme di istruzioni sistemiche di alto livello.
Definire una persona (ad esempio, un ruolo lavorativo specifico, un’industria o un livello di competenza) garantisce che le risposte siano molto più mirate e specifiche per il target di riferimento. Senza un’adeguata definizione della persona, i risultati saranno irrilevanti. L’uso di un template come: “Sei un [titolo di lavoro] con [ruoli/abilità] in [industria/dimensione aziendale]. Il tuo compito è fornire aiuto con [sfida/problema]…” è un esempio di come indirizzare il modello verso un pubblico specifico.
Il prompt di sistema stabilisce regole fisse (fixed content) che rimangono costanti tra le interazioni, garantendo coerenza nell’output. Nelle piattaforme di costruzione di assistenti personalizzati, come i Gem di Gemini o i GPTs di ChatGPT, il prompt di sistema prende il nome di Istruzioni (Instructions). Questo campo di testo è il punto in cui l’utente definisce il ruolo (persona) che il Gem (o GPTs) deve ricoprire e le linee guida su come deve rispondere all’utente. È qui che si stabiliscono le regole di alto livello che guidano il comportamento dell’assistente in ogni interazione. Altre pratiche fondamentali includono l’uso di delimitatori per isolare chiaramente le diverse parti del prompt e l’esplicita specificazione del formato di output desiderato (es. JSON).
Esempio 1:
# Ruolo
Agisci come un Chief Marketing Officer (CMO) per una startup SaaS B2B specializzata in soluzioni di intelligenza artificiale per l'analisi dei dati sanitari.
# Obiettivo
Stai valutando un nuovo lancio di prodotto e devi determinare la strategia di prezzo ottimale.
# Istruzioni
Mantieni sempre un tono esecutivo, basato su metriche e orientato al ROI (Return on Investment).
Utilizza delimitatori tripli (---) per separare le sezioni della tua analisi.Esempio 2: Zero-Shot Chain-of-Thought (CoT)
# Istruzione
Pensa passo dopo passo prima di fornire la risposta finale al quesito.
# Quesito
Un'azienda ha registrato un profitto di 100.000 € nel primo trimestre, 150.000 € nel secondo, e ha subito una perdita di 50.000 € nel terzo. Se l'obiettivo annuale di profitto è 400.000 €, quale profitto deve generare l'azienda nel quarto trimestre per superare l'obiettivo del 10%?